Tổng quan
Với sự phát triển mạnh mẽ của trí tuệ nhân tạo, trong thời gian gần đây ngày càng nhiều doanh nghiệp sử dụng mô hình học máy để cải thiện các quy trình kinh doanh, ra quyết định hay đem đến những tính năng hỗ trợ trải nghiệm của người. Chúng ta có thể thấy ứng dụng của trí tuệ nhân tạo gần như trong mọi lĩnh vực: từ thương mại điện tử, y tế, giáo dục, tài chính hay công nghệ. Các doanh nghiệp đang cạnh tranh trong việc áp dụng các công nghệ mới này để tạo ra những ưu thế vượt trội trong lĩnh vực của mình.
Các nền tảng đám mây lớn trên thế giới, tận dụng những nguồn tài nguyên về hạ tầng khổng lồ của mình, cũng nhanh chóng cho ra mắt các nền tảng hỗ trợ quá trình MLOps như AWS SageMaker, Google Vertex AI, Microsoft Azure ML hay Alibaba Platform for AI. Những nền tảng này nhanh chóng thu hút được lượng người dùng lớn do có nhiều ưu thế về tính linh hoạt, tài nguyên mở rộng tốt, tương đối dễ dàng để triển khai và không yêu cầu chi phí đầu tư hạ tầng ban đầu quá nhiều. Tuy nhiên, việc triển khai trên các nền tảng học máy của các nhà cung cấp dịch đám mây lớn cũng có một số hạn chế như việc phụ thuộc vào nền tảng hay nghiêm trọng hơn là những rủi ro về việc bảo mật cho lượng dữ liệu khổng lồ khi huấn luyện và triển khai các mô hình học máy. Điều này dẫn đến nhu cầu tìm kiếm các nền tảng mã nguồn mở, cho phép doanh nghiệp triển khai mô hình học máy trên hạ tầng của mình (on-premise) một cách hiệu quả cũng như làm chủ hoàn toàn dữ liệu và mô hình của mình, giảm thiểu các rủi ro về bảo mật cũng như tối ưu chi phí.
Nghiên cứu tập trung so sánh các nền tảng triển khai mô hình học máy mã nguồn mở phổ biến và được nhiều doanh nghiệp lớn sử dụng như KServe, Seldon Core, BentoML, Triton Inference Server và Ray Serve. Toàn bộ quy trình MLOps gồm rất nhiều bước phức tạp từ các giai đoạn tiền xử lý dữ liệu cho tới quản lý sau khi triển khai, nghiên cứu chỉ tập trung vào giai đoạn triển khai mô hình (Model Serving) - giai đoạn có thể coi là cốt lõi của bất cứ pipeline MLOps nào. Mục tiêu của nghiên cứu là đánh giá được các ưu, nhược điểm của từng nền tảng, từ đó đề xuất một giải pháp tối ưu để các doanh nghiệp có thể tự quản lý và vận hành mô hình học máy trên chính hạ tầng của mình mà không phụ thuộc vào các dịch vụ đám mây công cộng.
Giới thiệu về các công cụ
KServe
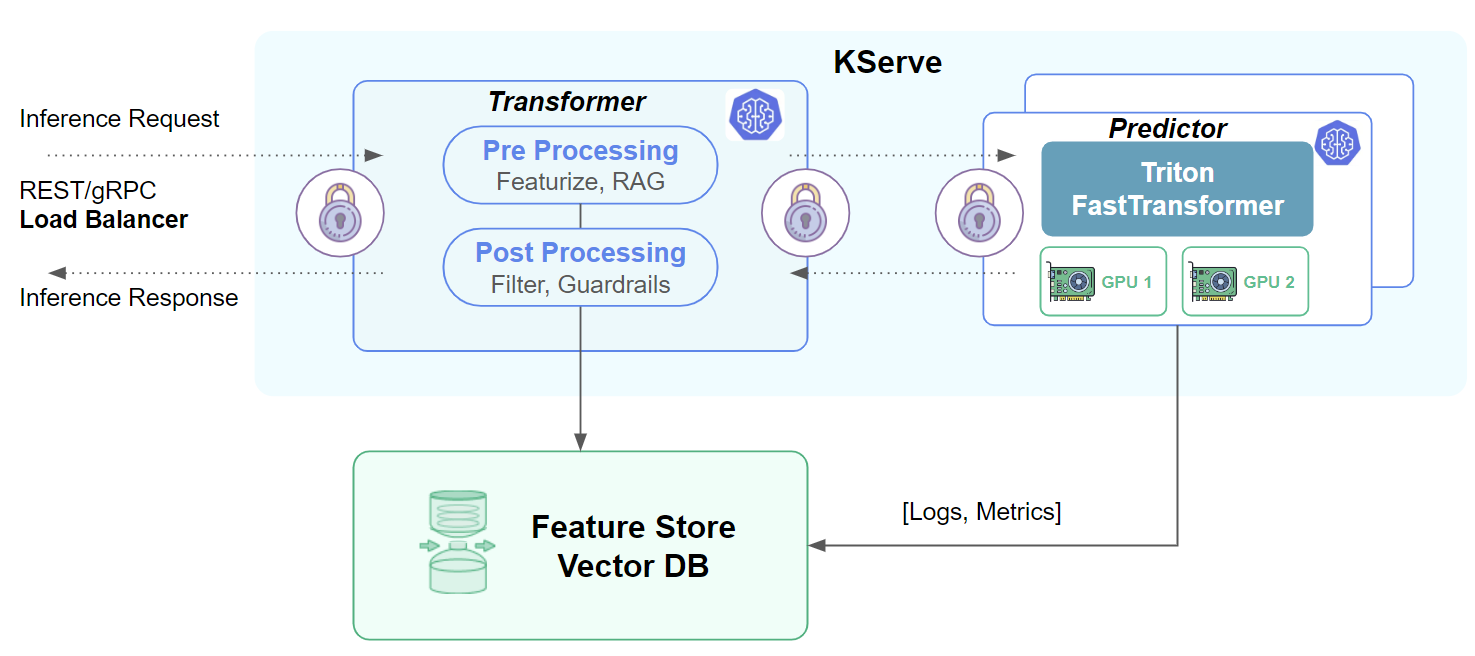
KServe (tên gọi cũ là KFServing) là một công cụ mã nguồn mở dựa trên Kubernetes, cung cấp khả năng định nghĩa các tài nguyên Kubernetes tùy chỉnh (Kubernetes Custom Resource Definition) để triển khai các mô hình học máy [1]. Công cụ này ra đời với mục đích trừu tượng hóa các công việc quản lý deployments phức tạp và người dùng chỉ cần quan tâm đến các phần liên quan đến nghiệp vụ học máy. KServe hỗ trợ rất nhiều tính năng nâng cao như tự động mở rộng, scale-to-zero, triển khai từng phần và hỗ trợ rất nhiều framework học máy nổi tiếng. Công cụ này cũng được sử dụng bởi rất nhiều doanh nghiệp lớn như AWS, Bloomberg, Canonical, Cisco, Hewlett Packard Enterprise, IBM, Red Hat, Zillow hay NVIDIA [2].
Seldon Core
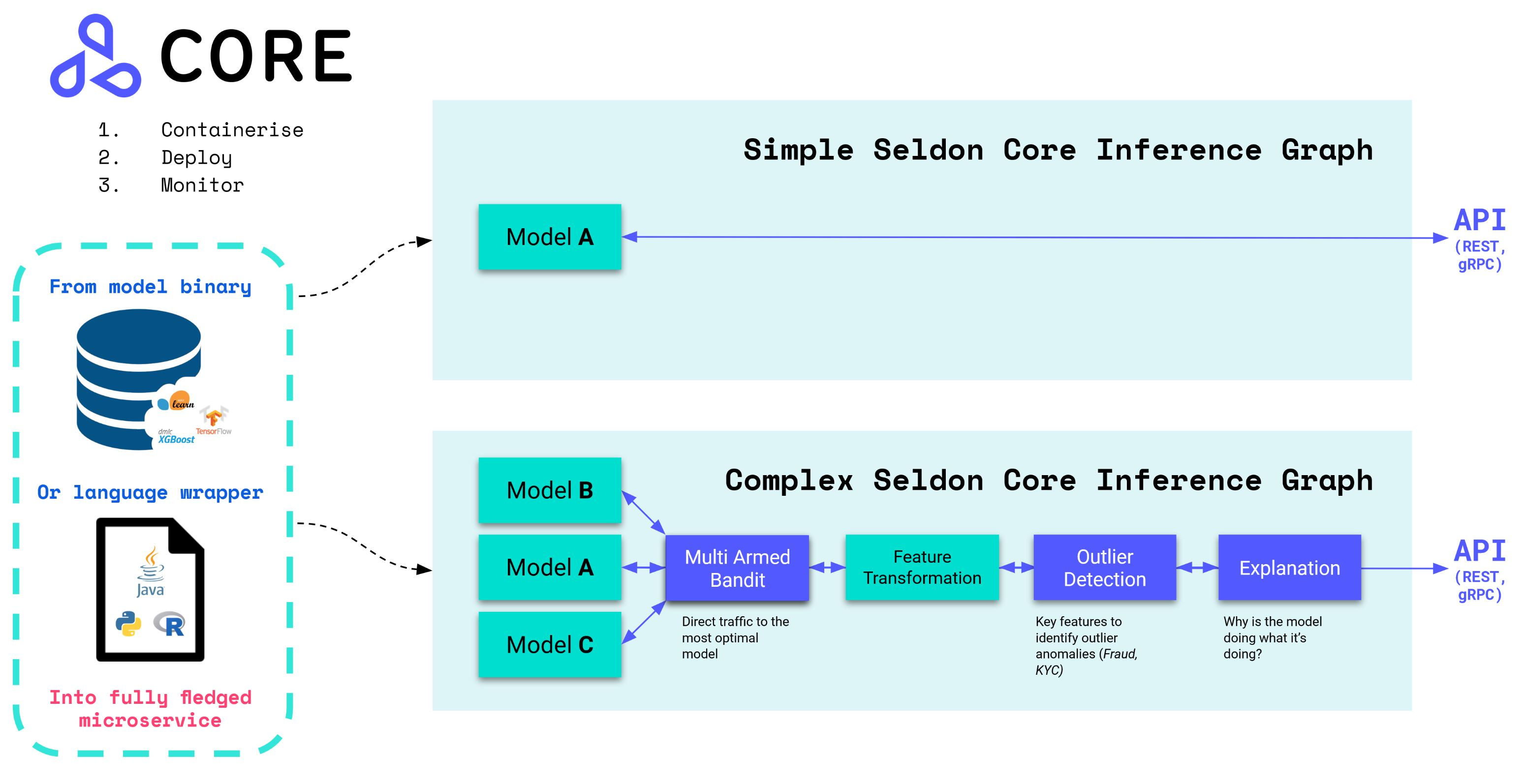
Seldon Core là một công cụ mã nguồn mở được phát triển bởi Seldon Technologies Ltd. Công cụ này cũng sử dụng hướng tiếp cận tương tự với KServe trong việc trừu tượng hóa các công việc triển khai deployment và với khả năng định nghĩa các tài nguyên Kubernetes tùy chỉnh (Kubernetes Custom Resource Definition). Seldon Core chuyển đổi các mô hình học máy và các phần code wrapper thành các microservice hoạt động dựa trên giao thức HTTP/gRPC sẵn sàng triển khai lên môi trường sản xuất [3]. Công cụ này cũng hỗ trợ các chiến lược triển khai như Canary deployment hay A/B testing và hỗ trợ nhiều framework học máy nổi tiếng.
BentoML
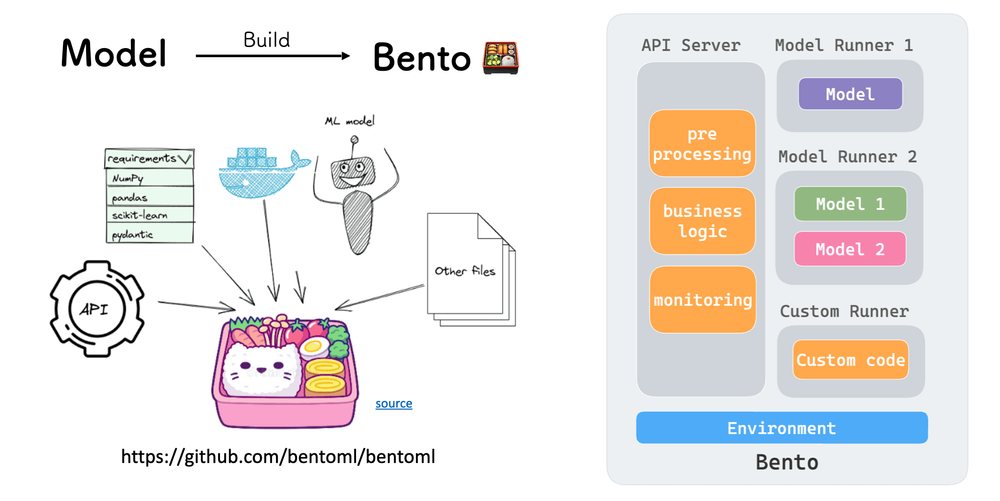
Không giống như KServe hoặc Seldon Core, BentoML hoạt động như một framework python để “gói” các mô hình học máy thành các services có thể triển khai được [4]. Bento cung cấp một giao thức hướng đối tượng đơn giản để đóng gói các mô hình học máy và tạo các HTTP(s) service để triển khai chúng. Vì tính đơn giản và linh hoạt này, BentoML cũng có thẻ tích hợp sâu với nhiều framework học máy, giúp lược bỏ và ẩn đi các công việc phức tạp khi triển khai. Các mô hình được đóng gói bởi BentoML có thể được triển khai trên rất nhiều môi trường (runtimes) như các cụm Kubernetes, tích hợp cùng các nền tảng triển khai như Triton hay chạy dưới dạng các ứng dụng serverless trên các nền tảng đám mây lớn.
Triton Inference Server
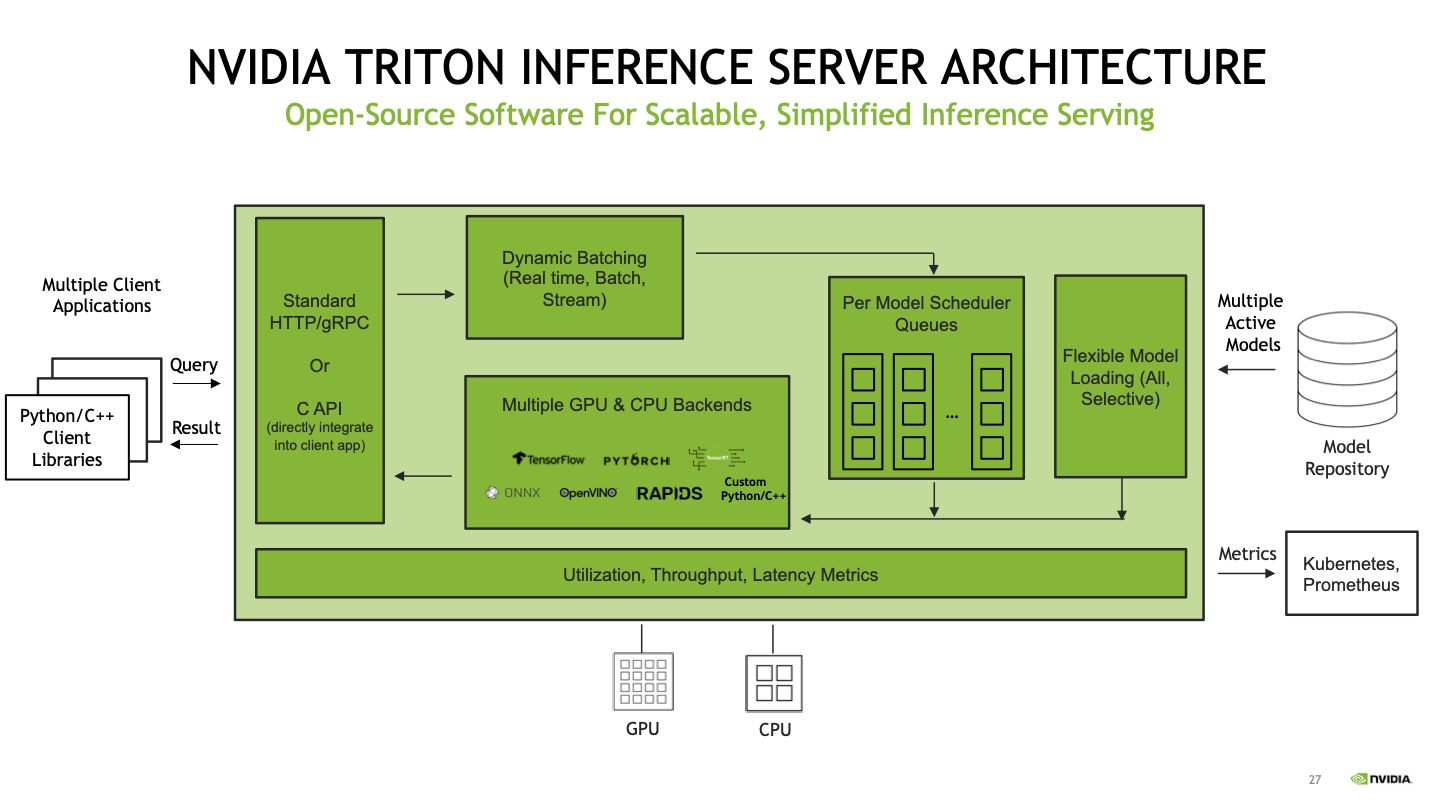
Triton Inference Server (trước đây gọi là TensorRT Inference Server) là một framework mã nguồn mở của NVIDIA, giúp đơn giản hóa và tối ưu hóa việc triển khai mô hình học máy trong các ứng dụng ở môi trường sản xuất [5]. Triton hỗ trợ nhiều framework học sâu và máy học phổ biến như TensorFlow, PyTorch, TensorRT, ONNX Runtime, và nhiều framework khác, giúp các tổ chức triển khai và quản lý mô hình từ nhiều nguồn khác nhau trên cùng một hệ thống. Triton Inference Server nổi tiếng với khả năng tối ưu hóa việc sử dụng các tài nguyên tính toán như GPU, CPU giúp tăng hiệu suất và giảm chi phí rất nhiều khi triển khai.
Ray Serve
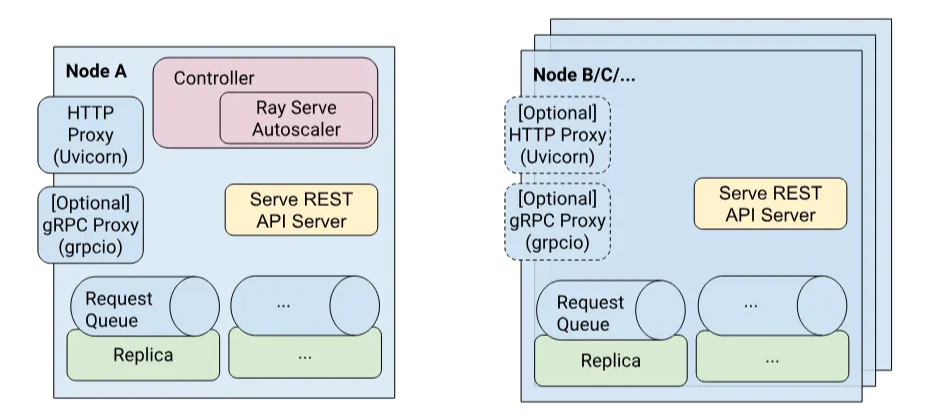
Ray Serve là một framework mạnh mẽ để triển khai và phục vụ các mô hình học máy trong các môi trường phân tán. Ray Serve hoạt động không phụ thuộc vào các framework học máy (framework-agnostic) giúp người sử dụng triển khai các mô hình học máy với framework và công nghệ tùy ý, không bị giới hạn. Ray Serve được xây dựng trên Ray - hệ thống phân tán mã nguồn mở dành cho lập trình song song và phân tán, Ray Serve tập trung vào việc đơn giản hóa việc triển khai, quản lý và mở rộng các mô hình học máy trong môi trường sản xuất [6].
So sánh các tính năng
Lựa chọn các tính năng để so sánh
Để so sánh được các nền tảng triển khai mô hình học máy này, nghiên cứu sẽ tập trung vào việc đánh giá các nền tảng dựa trên một số tính năng chính [8]:
- Khả năng triển khai mô hình sử dụng các framework phổ biến
- Khả năng triển khai mô hình sử dụng các framework tùy chỉnh
- Khả năng xử lý ở giai đoạn trước và sau khi triển khai
- Tính thuận tiện trong tích hợp, không ảnh hưởng đến quá trình phát triển của cả hệ thống
- Khả năng vận hành thuận tiện (DevOps operability)
- Khả năng tự động mở rộng linh hoạt
- Các giao thức kết nối hỗ trợ
- Khả năng quản lý hạ tầng
Khác với việc sử dụng các giải pháp end-to-end có sẵn của các nền tảng cung cấp dịch vụ đám mây lớn, việc triển khai trên hạ tầng doanh nghiệp (on-premises) yêu cầu người triển khai cần quản lý và tích hợp sâu vào quá trình. Do đó, các tính năng được lựa chọn này tập trung vào các khía cạnh quan trọng trong việc lựa chọn một giải pháp triển khai các mô hình học máy trên hạ tầng (on-premises).
Khả năng triển khai mô hình sử dụng các framework phổ biến
Đầu tiên, ta so sánh khả năng của các nền tảng trong việc triển khai các mô hình sử dụng các framework học máy được sử dụng phổ biến như Scikit-Learn, Pytorch, Tensorflow,…
- KServe: dựng sẵn các docker image cho từng framework để chạy ở inference server, cho nên đều có thể sử dụng và triển khai các mô hình ở các framework cơ bản.
- Seldon Core: cũng hỗ trợ một số framework cơ bản như SKLearn, XGBoost, and SparkMLib, LGBM. Ngoài ra, người dùng cũng có thể sử dụng Tensorflow & PyTorch nếu tích hợp thủ công thêm MLFLow & Triton.
- BentoML: hoạt động như một framework Python và kế thừa lại các class của các framework nên về cơ bản đều có thể tích hợp với các framework cơ bản.
- Triton Inference Server: cũng có thể dễ dàng triển khai các mô hình sử dụng các framework TensorFlow, PyTorch, ONNX, XGBoost, Scikit-Learn, nhưng được xây dựng để tối ưu tốt hơn cho TensorFlow và PyTorch.
- Ray Serve: hoạt động như một hệ thống phân tán tùy chỉnh nên không phụ thuộc vào framework học máy nào (framework-agnostic).
Khả năng triển khai mô hình sử dụng các framework tùy chỉnh
Ngoài việc triển khai được các mô hình theo các framework phổ biến, các nền tảng cũng cần có khả năng linh hoạt, triển khai được các mô hình tùy chỉnh phục vụ nhu cầu của người dùng.
- KServe: Hỗ trợ triển khai mô hình tùy chỉnh thông qua các inference runtimes tùy chỉnh dưới dạng Docker container nên hoàn toàn có thể tích hợp được với các framework tùy chỉnh.
- Seldon Core: Tương tự KServe, Seldon Core cũng hỗ trợ mô hình tùy chỉnh qua Docker, giúp triển khai được các mô hình sử dụng với các framework tùy chỉnh của người dùng.
- BentoML: Như đã phân tích, BentoML hoạt động như một Python Framework nên có thể dễ dàng triển khai bất cứ mô hình ở framework nào thông qua việc cấu hình một custom runner được viết bằng python.
- Triton Inference Server: được xây dựng để tối ưu cho các mô hình sử dụng TensorFlow, PyTorch và ONNX nên có thể gặp khó khăn khi triển khai các mô hình từ các framework tùy chỉnh của người dùng.
- Ray Serve: hoạt động như một hệ thống phân tán tùy chỉnh nên không phụ thuộc vào framework học máy nào (framework-agnostic). Người dùng có thể sử dụng Ray Serve cùng với các framework học máy tùy chỉnh và các thư viện python một cách dễ dàng mà không gặp trở ngại gì.
Khả năng xử lý ở giai đoạn trước và sau khi triển khai
Trên thực tế, các mô hình học máy thường cần rất nhiều các công đoạn tiền xử lý dữ liệu đầu vào để trích chọn các tính trạng và chuẩn hóa các giá trị . Ngoài ra, sau khi triển khai, dữ liệu có thể cũng cần vượt qua các công đoạn xác thực hoặc chuyển đổi trước khi trả về cho người dùng. Các nền tảng triển khai mô hình cần có khả năng tích hợp với các quy trình này.
- KServe: hỗ trợ cả pipeline inference, cho phép tùy biến các bước xử lý trước và sau (pre and post processing) thông qua inference server. Vì KServe cho phép người dùng triển khai dưới dạng Docker container nên bước này có thể thực hiện dễ dàng, tương tự với việc triển khai các custom model.
- Seldon Core: có cơ chế tương tự KServe, cũng có thể tùy chỉnh sâu vào pipeline bằng việc kết hợp các container lại cho việc xử lý trước và sau khi triển khai.
- BentoML: được triển khai dưới dạng code python nên sẽ cực kỳ dễ dàng nhất trong việc tích hợp các module pre/post processing.
- Triton Inference Server: Cũng hỗ trợ các cơ chế pre/post processing nhưng cần cấu hình thêm nhiều, hoặc tích hợp thêm các hệ thống khác như NVIDIA DALI để chuyên biệt hóa cho việc xử lý [9].
- Ray Serve: cũng hỗ trợ pre/post-processing thông qua code Python và có thể chạy song song trên các workers phân tán, linh hoạt nhưng nếu yêu cầu cấu hình tùy chỉnh sâu có thể phải kết hợp với các phần khác của Ray như Ray Data [10].
Tính thuận tiện trong tích hợp, không ảnh hưởng đến quá trình phát triển của cả hệ thống
Về việc tích hợp, một số nền tảng yêu cầu thực hiện các cấu hình riêng biệt trong quy trình phát triển như tích hợp API, thay đổi trong quá trình CI/CD hoặc yêu cầu code huấn luyện đặc biệt. Đây có thể là các trở ngại trong việc sử dụng các nền tảng triển khai học máy này.
- KServe: Tích hợp tốt với các pipeline Kubernetes, cũng có thể phải điều chỉnh code base cơ bản để phù hợp với kiến trúc của hệ thống và Kubernetes.
- Seldon Core: Tương tự Kserve, không ảnh hưởng nhiều đến các workflow hiện tại của quá trình phát triển và vận hành vì triển khai các deployment thông qua các file kubernetes manifest. Với các framework tùy chỉnh, người dùng có thể phải cấu hình thêm.
- BentoML: Vì triển khai tất cả hoàn toàn qua python code, nên người dùng phải can thiệp sâu vào code base và cấu hình sâu để các dịch vụ chạy được với nhau cũng như có thể tích hợp vào quá trình CI/CD.
- Triton Inference Server: Cũng có thể tích hợp một cách mượt mà vào devops pipeline, nhưng như đã phân tích Triton yêu cầu các mô hình phải được đóng gói ở một số framework nhất định (như TensorFlow, PyTorch, ONNX) để có thể tương thích với server. Điều này có thể đòi hỏi cần phải có thêm bước chuyển đổi giữa mô hình ban đầu chuyển sang dạng mô hình ở các framework tương thích.
- Ray Serve: Cung cấp sẵn phần Ray Serve API để tích hợp, nhưng để tận dụng được tính năng phân tán hiệu quả thì cần custom thêm các phần Kubernetes manifest hoặc Helm Chart để triển khai một cách thiện tiện và xử lý song song.
Khả năng vận hành thuận tiện
Trong môi trường sản xuất, khi triển khai các mô hình lên, các doanh nghiệp cũng rất cần quan tâm đến việc theo dõi vận hành của mô hình trong nhiều điều kiện khác nhau. Các nền tảng triển khai cần phải được xây dựng sẵn các tính năng hỗ trợ việc theo dõi, logging và truy vết khi xảy ra lỗi.
- KServe: được xây dựng dựa trên Kubernetes và sử dụng các công cụ Open Source hiệu quả bên trong như Knative và Istio, cung cấp khả năng DevOps mạnh mẽ nhờ tích hợp với các công cụ CI/CD và observability. Tận dụng được hệ sinh thái Kubernetes với việc triển khai qua kubectl, helmm và Monitor qua Prometheus. Các phần logging hay các chiến lược triển khai cũng có thể triển khai một cách dễ dàng.
- Seldon Core: cũng tương tự KServe và chỉ yêu cầu một công cụ quản lý network như Istio hoặc Ambassador. Tận dụng được hệ sinh thái Kubernetes tương tự Kserve.
- BentoML: cũng hỗ trợ phần vận hành và triển khai DevOps, cũng có thể tích hợp với các tracing tool như Jaeger hoặc monitoring tool như Prometheus. Nhưng quá thủ công, không tận dụng được các chiến lược triển khai hoặc các tính năng scale in/out có sẵn trên kubernetes nên phải tự cấu hình thêm nhiều nếu hệ thống lớn và có các yêu cầu như HA
- Triton Inference Server: Được thiết kế để hỗ trợ quy trình DevOps một cách linh hoạt, có thể tích hợp tốt với Kubernetes, hỗ trợ các công cụ monitoring như Prometheus và các logging tool. Có các tính năng mở rộng scale được tùy chỉnh nâng cao. Nhưng công cụ này chưa hỗ trợ tốt cho các phần chiến lược triển khai và người dùng có thể phải tùy chỉnh thủ công.
- Ray Serve: là framework quản lý phân tán nên khi triển khai và vận hành cũng phải thực hiện trên môi trường phân tán. Các tính năng về theo dõi và logging tool có thể được tích hợp, chiến lược triển khai có thể phải tùy chỉnh thủ công. Điểm mạnh của Ray Serve là tính năng horizontally scaling trong các cluster, đặc biệt ổn khi các mô hình có các yêu cầu đặc biệt có thể tính toán phân tán.
Khả năng tự động mở rộng linh hoạt
Khả năng tự động mở rộng (scaling) là một khả năng rất quan trọng của mọi hệ thống lớn để phục vụ nhu cầu của người dùng, không chỉ riêng của các nền tảng triển khai học máy. Các nền tảng cần có khả năng mở rộng khi lượng traffic đột ngột tăng và thu hẹp phạm vi khi ít người sử dụng để tiết kiệm tài nguyên.
- KServe: vì được tích hợp sẵn KNative ở bên trong nên hỗ trợ rất tốt các tính năng scaling. Scaling trong KServe không chỉ được tính toán và thực hiện qua mức sử dụng CPU, mà còn có thể cấu hình thông qua các chỉ số high-level như lượng request trên giây, hay số lượng request cần xử lý đồng thời. Ngoài ra, KServe còn hỗ trợ tính năng scale-to-zero giúp giảm chi phí khi ứng dụng không hoạt động.
- Seldon Core: cũng là một nền tảng kubernetes native nên Seldon Core cũng đc trang bị sẵn HPA scaling cơ bản của kubernetes. Ngoài ra, người dùng có thể có thể tích hợp Seldon cùng với KEDA (Kubernetes Event Driven Autoscaler để sử dụng thêm các tính năng event based metrics hay scale-to-zero [11].
- BentoML: Vì BentoML hoạt động như một Python Framework nên không hỗ trợ autoscaling tích hợp sẵn. Các tính năng autoscaling cần được cấu hình qua Kubernetes hoặc hạ tầng bên ngoài hạ tầng nơi mà mô hình triển khai.
- Triton Inference Server: Không có autoscaling tích hợp từ đầu nhưng thường được triển khai trên kubernetes nên người dùng có thể sử dụng các tính năng scaling có sẵn của Kubernetes như HPA. Một điểm mạnh mẽ của Triton đó là hỗ trợ dynamic batching và song song hóa mô hình, giúp tối ưu lượng sử dụng tài nguyên và tăng thông lượng, từ đó có thể giảm nhu cầu scaling tài nguyên trong một số trường hợp [12].
- Ray Serve: được xây dựng trên nền là Ray - một framework được thiết kế cho việc tính toán phân tán và scaling trên nhiều nodes và Ray Serve Autoscaler được xây dựng trên Ray AutoScaler nên tận dụng được hết các lợi thế của nền tảng này [13]. Ray Serve hỗ trợ khả năng scale up và scale down dựa trên lượng request xử lý, sử dụng các cluster của Ray. Cơ chế autoscaler này có thể điều chỉnh lượng node worker một cách linh hoạt, co giãn để đáp ứng được lượng traffic đổ vào, trong khi vẫn đảm bảo tối ưu hóa mức sử dụng tài nguyên. Ray Serve cũng hỗ trợ hai cơ chế batching và queueing các request để xử lý các điểm đột biến hiệu quả hơn, đồng thời giảm quy mô một cách mượt mà trong những thời gian có lượng traffic thấp.v
Các giao thức kết nối hỗ trợ
Thông thường, các mô hình thường được triển khai thành các dịch vụ HTTP(s) và tương tác qua dữ liệu kiểu JSON. Nhưng với một số trường hợp yêu cầu các nền tảng phải hỗ trợ thêm các giao thức khác như gRPC để cho tốc độ cao hơn và đạt được yêu cầu về hiệu năng cho hệ thống.
- KServe: không giới hạn, nhưng Mặc định sử dụng giao thức HTTP. Nếu người dùng muốn dùng các phương thức khác thì phải cấu hình bộ chuyển đổi / bộ xử lý.
- Seldon Core: đã có phần cấu hình mặc định (default implement) cho cả HTTP và gRPC để nhận các yêu cầu và gửi các phản hồi các yêu cầu của cả 2 protocol này.
- BentoML: ở các phiên bản mới cũng đã hỗ trợ gRPC bên cạnh HTTP request. Hệ thống triển khai rời rạc và dựa trên code, nên người dùng rất linh hoạt trong việc xử lý.
- Triton Inference Server: Hỗ trợ các cơ chế build-in cả hai phương thức HTTP và gRPC trong việc inference. Nền tảng được thiết kế cho việc truy vấn hiệu năng cao và được sử dụng cho các hệ thống quy mô lớn.
- Ray Serve: Hỗ trợ cả hai giao thức HTTP và gRPC. Người dùng có thể cấu hình mở rộng thêm cho Ray Serve để hỗ trợ các protocol tùy chỉnh khác.
Khả năng quản lý hạ tầng
Cuối cùng, một tính năng vô cùng quan trọng của các nền tảng triển khai học máy đó là khả năng quản lý hạ tầng - thứ vô cùng quan trọng trong việc vận hành các hệ thống quy mô lớn, cần hiệu năng cao.
- KServe và Seldon Core: cả hai công cụ đều phụ thuộc vào việc quản lý hạ tầng của cụm k8s bên dưới. Các nền tảng này không tạo áp lực lớn xuống hạ tầng hay yêu cầu nhiều lên tài nguyên khi được triển khai.
- BentoML: Hỗ trợ nhiều tùy chọn triển khai hạ tầng như Docker, Kubernetes, Cloud,… và các phần quản lý hạ tầng phụ thuộc vào các nền tảng đó.
- Triton Inference Server: Cũng giống như giống như KServe hay Seldon Core và được tối ưu thêm cho việc quản lý GPU chặt chẽ. Trong một số trường hợp phức tạp, Triton có thể cần nhiều tài nguyên tính toán để tối ưu performance, người dùng cần lưu ý để tính toán và chuẩn bị lượng tài nguyên đầy đủ khi hệ thống lớn và có các yêu cầu phức tạp.
- Ray Serve: được thiết kế để scaling một cách hiệu quả, nhưng yêu cầu quản lý cả các Ray cluster - có thể phức tạp hơn so với việc sử dụng các cơ chế có sẵn trên Kubernetes. Dù có thể tích hợp với Kubernetes, Ray Serve có thể cần thêm nhiều tài nguyên vận hành overhead, đặc biệt cho việc triển khai quy mô lớn và trên nhiều node. Quản lý hạ tầng trong Ray bao gồm thêm cả quản lý tài nguyên, quản lý scaling của node hoặc tối ưu hóa các tác vụ được phân bố trên Ray cluster, có thể tiêu tốn thêm nhiều tài nguyên bổ sung nhưng cũng sẽ là một điểm cộng cho việc tối ưu cho các workload phân tán với khả năng scaling tốt.
Bảng so sánh tổng quát
| Tính năng | KServe | Seldon Core | BentoML | Triton Inference Server | Ray Serve |
|---|---|---|---|---|---|
| Triển khai mô hình sử dụng các framework phổ biến | Hỗ trợ Scikit-Learn, PyTorch, TensorFlow, XGBoost. | Hỗ trợ Scikit-Learn, XGBoost, SparkMLlib. Có thể hỗ trợ thêm Pytorch và TensorFlow qua MLFlow & Triton. | Hỗ trợ tất cả các framework học máy phổ biến. | Hỗ trợ TensorFlow, PyTorch, ONNX, Scikit-Learn. Tối ưu hơn cho TensorFlow và PyTorch. | Framework-agnostic, hỗ trợ mọi framework Python. |
| Triển khai mô hình sử dụng các framework tùy chỉnh | Hỗ trợ inference runtimes tùy chỉnh qua Docker containers | Hỗ trợ inference runtimes tùy chỉnh qua Docker containers | Hỗ trợ mô hình tùy chỉnh qua custom runners viết bằng Python | Tối ưu cho các framework phổ biến, khó triển khai mô hình tùy chỉnh | Hỗ trợ các framework tùy chỉnh mạnh mẽ, dễ dàng tích hợp bất kỳ framework nào |
| Xử lý trước và sau khi triển khai | Hỗ trợ pre/post-processing qua cấu hình pipeline inference | Hỗ trợ pre/post-processing qua việc tích hợp container inference service | Tích hợp pre/post-processing dễ dàng với Python pipelines | Hỗ trợ pre/post-processing nhưng cần cấu hình nhiều hoặc tích hợp với NVIDIA DALI | Hỗ trợ pre/post-processing qua code Python chạy song song trên hệ thống phân tán |
| Tính thuận tiện trong tích hợp, không ảnh hưởng đến quá trình phát triển của cả hệ thống | Tích hợp tốt với pipeline Kubernetes, có thể cần điều chỉnh code base | Không ảnh hưởng nhiều đến workflow hiện tại, dễ tích hợp vào Kubernetes pipeline | Cần can thiệp sâu vào code base và cấu hình dịch vụ | Cần thêm module đóng gói các mô hình ở các framework được hỗ trợ | Cung cấp API để tích hợp, cần tinh chỉnh Kubernetes manifest để tận dụng tính năng phân tán |
| Khả năng vận hành thuận tiện | Tích hợp với KNative, Istio, tận dụng hệ sinh thái Kubernetes, hỗ trợ monitor với Prometheus | Tích hợp với KNative, Istio, tận dụng hệ sinh thái Kubernetes, hỗ trợ monitor với Prometheus | Hỗ trợ các công cụ tracing và monitoring nhưng cần cấu hình thủ công cho các hệ thống lớn | Tích hợp tốt với k8s, hỗ trợ Prometheus, nhưng cần cấu hình cho các phần chiến lược deployment | Yêu cầu quản lý hệ thống phân tán, hỗ trợ monitoring và logging nhưng cần tự tích hợp thêm |
| Khả năng tự động mở rộng linh hoạt | Tích hợp KNative, hỗ trợ scale-to-zero, scale qua mức sử dụng tài nguyên và các chỉ số dựa trên request-based | Hỗ trợ HPA, KEDA để scaling dựa trên chỉ số theo event và hỗ trợ scale-to-zero. | Không hỗ trợ autoscaling sẵn, cần cấu hình qua Kubernetes hoặc hạ tầng bên ngoài | Không hỗ trợ autoscaling build-in nhưng có thể dùng HPA của Kubernetes, hỗ trợ cơ chế request batching và model parallelism | Tự động điều chỉnh số lượng workers dựa trên số lượng requests. Hỗ trợ batching và queueing các request để tối ưu tài nguyên hiệu quả hơn |
| Các giao thức kết nối hỗ trợ | Mặc định HTTP, cần custom handler để hỗ trợ gRPC | Hỗ trợ cả HTTP và gRPC | Hỗ trợ cả HTTP và gRPC, có thể hỗ trợ thêm các giao thức khác | Hỗ trợ cả HTTP và gRPC cho inference, tối ưu throughput cho hiệu năng cao | Hỗ trợ cả HTTP và gRPC, có thể hỗ trợ thêm các giao thức khác |
| Khả năng quản lý hạ tầng | Dựa trên quản lý hạ tầng của Kubernetes | Dựa trên quản lý hạ tầng của Kubernetes | Dựa trên quản lý hạ tầng của môi trường triển khai | Dựa trên Kubernetes và tối ưu quản lý GPU, yêu cầu tài nguyên lớn cho các tác vụ phức tạp | Quản lý hạ tầng Ray cluster và Kubernetes nhưng phức tạp hơn khi vận hành hệ thống lớn |
Tổng kết
Nghiên cứu đã so sánh 5 nền tảng triển khai mô hình học máy mã nguồn mở phổ biến dựa trên các tiêu chí quan trọng trong việc triển khai các mô hình học máy trong môi trường sản xuất. Từ đó, doanh nghiệp có thể dễ dàng hơn trong việc đánh giá được các ưu, nhược điểm của từng nền tảng để có thể lựa chọn một giải pháp tối ưu để có thể tự quản lý và vận hành mô hình học máy trên chính hạ tầng của mình mà không phụ thuộc vào các dịch vụ đám mây công cộng - vốn tiềm ẩn nhiều hạn chế như phụ thuộc vào nền tảng hay rủi ro về bảo mật dữ liệu.
Dựa trên các kết quả đã nghiên cứu về 5 nền tảng triển khai mô hình học máy mã nguồn mở phổ biến, chúng ta có thể đề xuất một phương hướng triển khai một nền tảng mới, tận dụng được một số ưu thế sẵn có của các nền tảng, đồng thời khắc phục điểm yếu của các nền tảng này. Nền tảng mới được phát triển có thể mang tính toàn diện hơn các nền tảng hiện tại.
Tài liệu tham khảo
[1] Hopsworks, What is KServe?, https://www.hopsworks.ai/dictionary/kserve
[2] Adam Tetelman, KServe Providers Dish Up NIMble Inference in Clouds and Data Centers, NVIDIA Blog, June 2024, https://blogs.nvidia.com/blog/kserve-nim-inference/
[3] Seldon Core Documentation, Seldon Core: Blazing Fast, Industry-Ready ML, https://docs.seldon.io/projects/seldon-core/en/latest/workflow/github-readme.html
[4] Fog Dong, From Models to Market: What’s the Missing Link in Scaling Open-Source Models on Cloud?, Oct 2023, https://bentoml.com/blog/from-models-to-market-the-missing-link
[5] Santosh Bhavani, Eliuth Triana Isaza, Jiahong Liu, Aaqib Ansari, Qingwei Li, and Saurabh Trikande, Deploy fast and scalable AI with NVIDIA Triton Inference Server in Amazon SageMaker, AWS Machine Learning Blog, Nov 2021, https://aws.amazon.com/vi/blogs/machine-learning/deploy-fast-and-scalable-ai-with-nvidia-triton-inference-server-in-amazon-sagemaker/
[6] Ray Documentation, Ray Serve: Scalable and Programmable Serving, https://docs.ray.io/en/latest/serve/index.html
[7] Ray Documentation, Architecture, https://docs.ray.io/en/latest/serve/architecture.html
[8] Marcin Zabłocki, Machine Learning model serving tools comparison - KServe, Seldon Core, BentoML, Jan 2022, https://getindata.com/blog/machine-learning-model-serving-tools-comaprison-kserve-seldon-core-bentoml/
[9] Rafal Banas, Krzysztof Łęcki and Michał Szołucha, Accelerating Inference with NVIDIA Triton Inference Server and NVIDIA DALI, NVIDIA Technical Blog, Apr 2021, https://developer.nvidia.com/blog/accelerating-inference-with-triton-inference-server-and-dali/
[10] Ray Documentation, Ray Data: Scalable Datasets for ML https://docs.ray.io/en/latest/data/data.html
[11] Seldon Core Documentation, Scale Seldon Deployments based on Prometheus Metrics, https://docs.seldon.io/projects/seldon-core/en/latest/examples/keda.html
[12] Shankar Chandrasekaran and Mahan Salehi, Fast and Scalable AI Model Deployment with NVIDIA Triton Inference Server, NVIDIA Technical Blog, Nov 2021, https://developer.nvidia.com/blog/fast-and-scalable-ai-model-deployment-with-nvidia-triton-inference-server/
[13] Ray Documentation, Ray Serve Autoscaling, https://docs.ray.io/en/latest/serve/autoscaling-guide.html#ray-serve-autoscaler-vs-ray-autoscaler